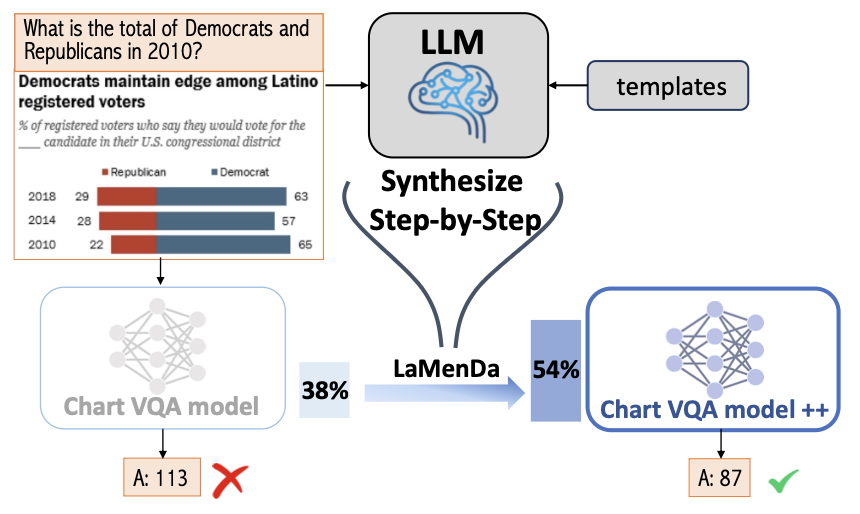
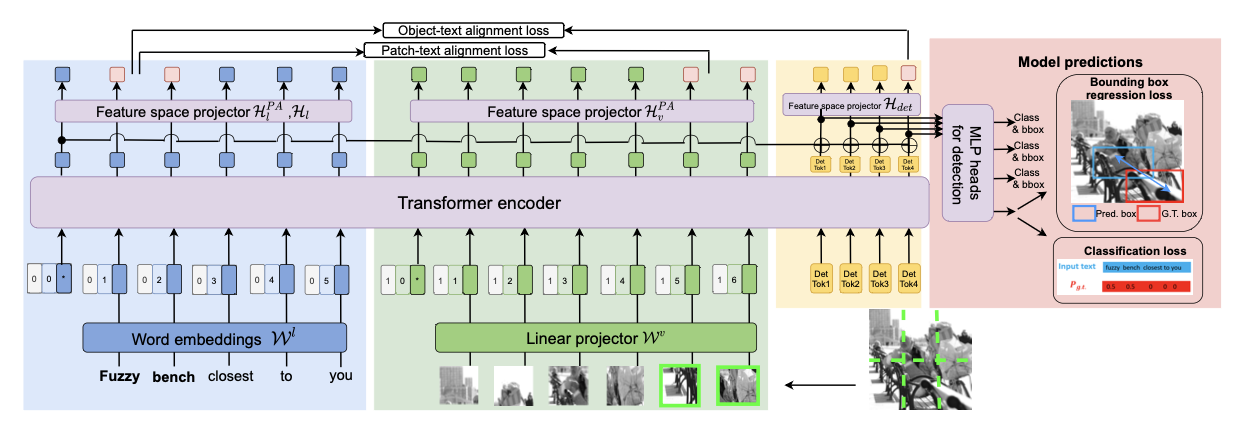
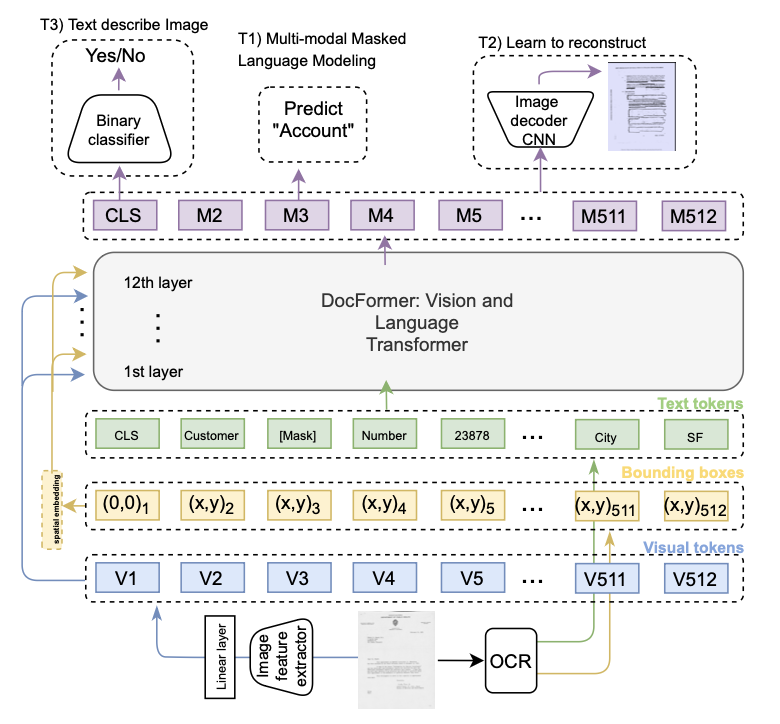
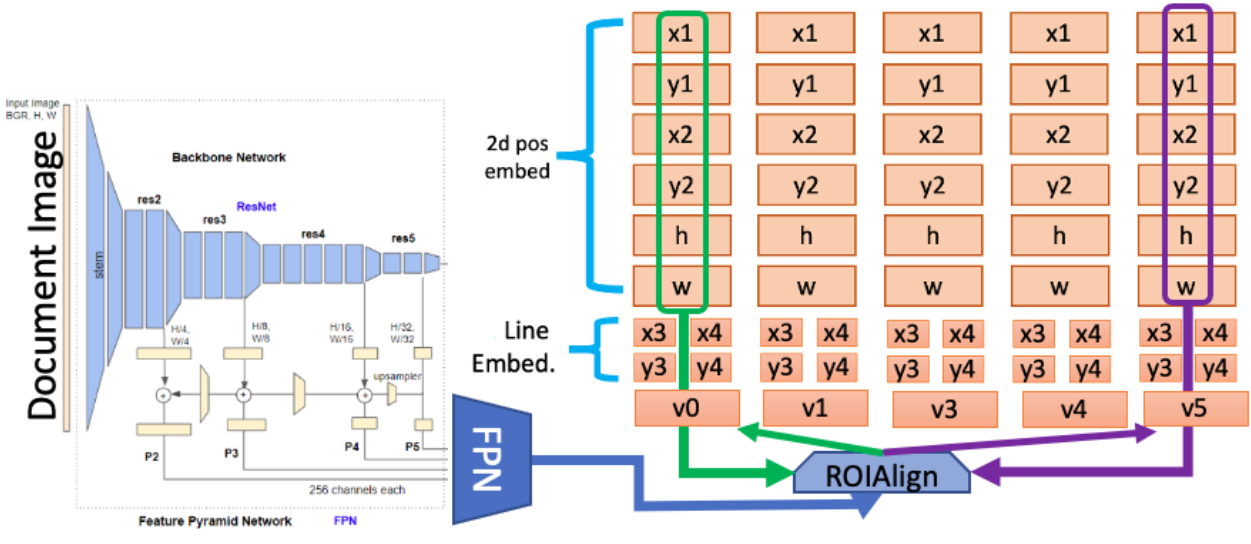
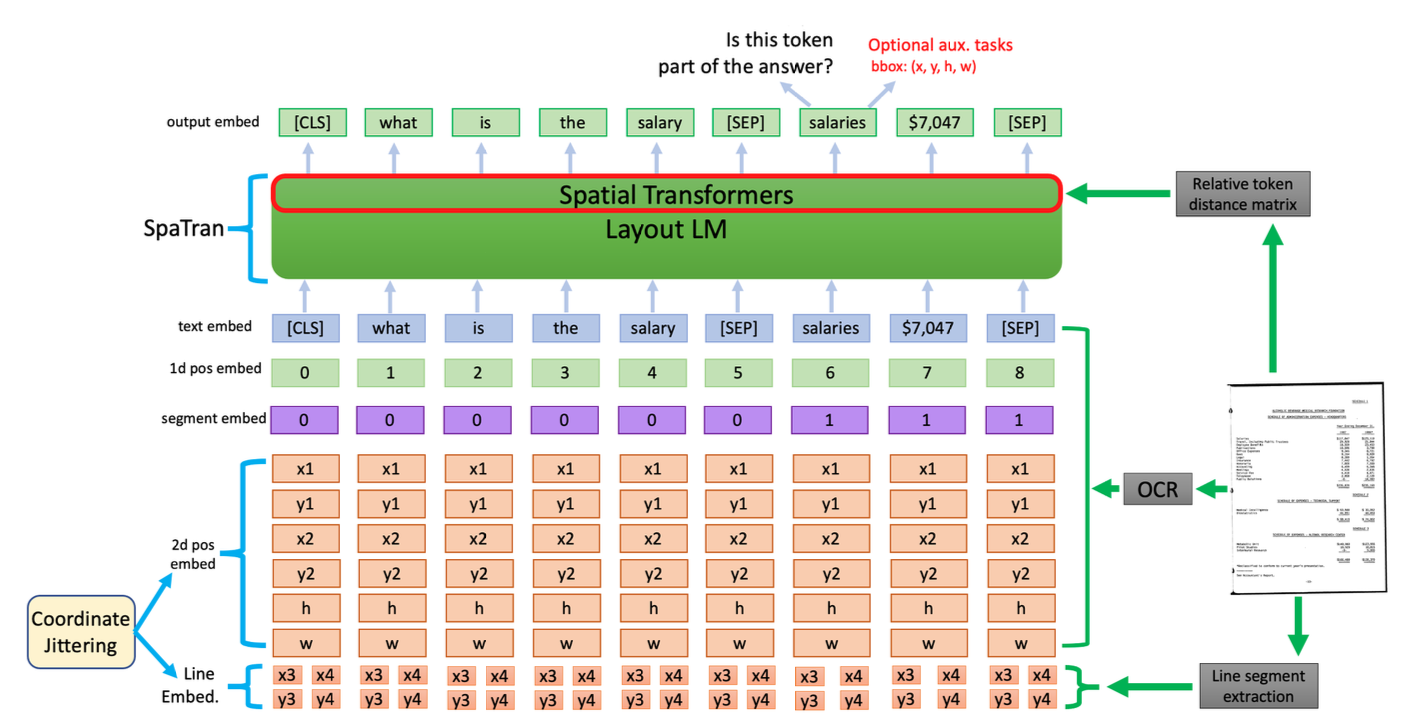
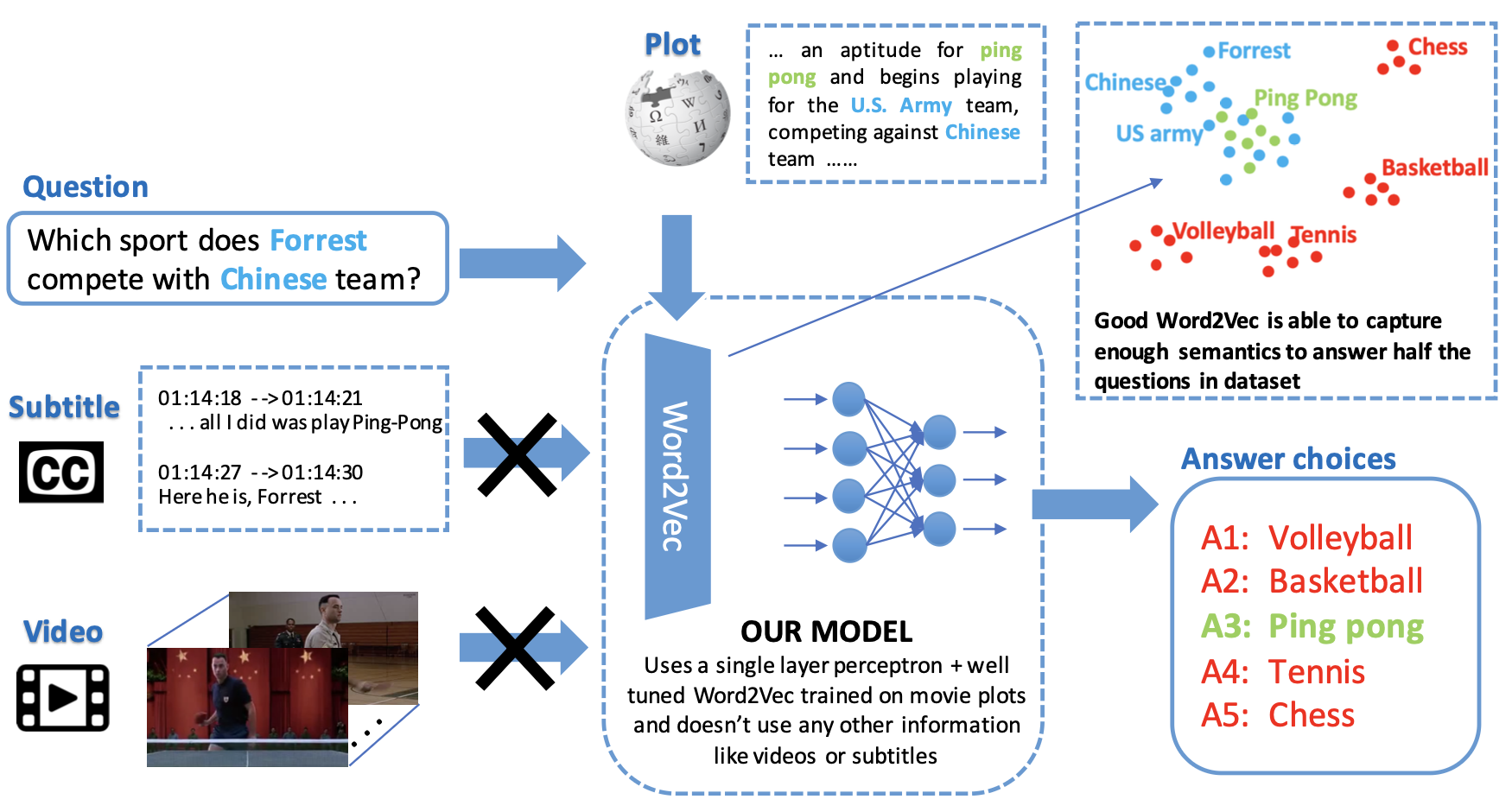
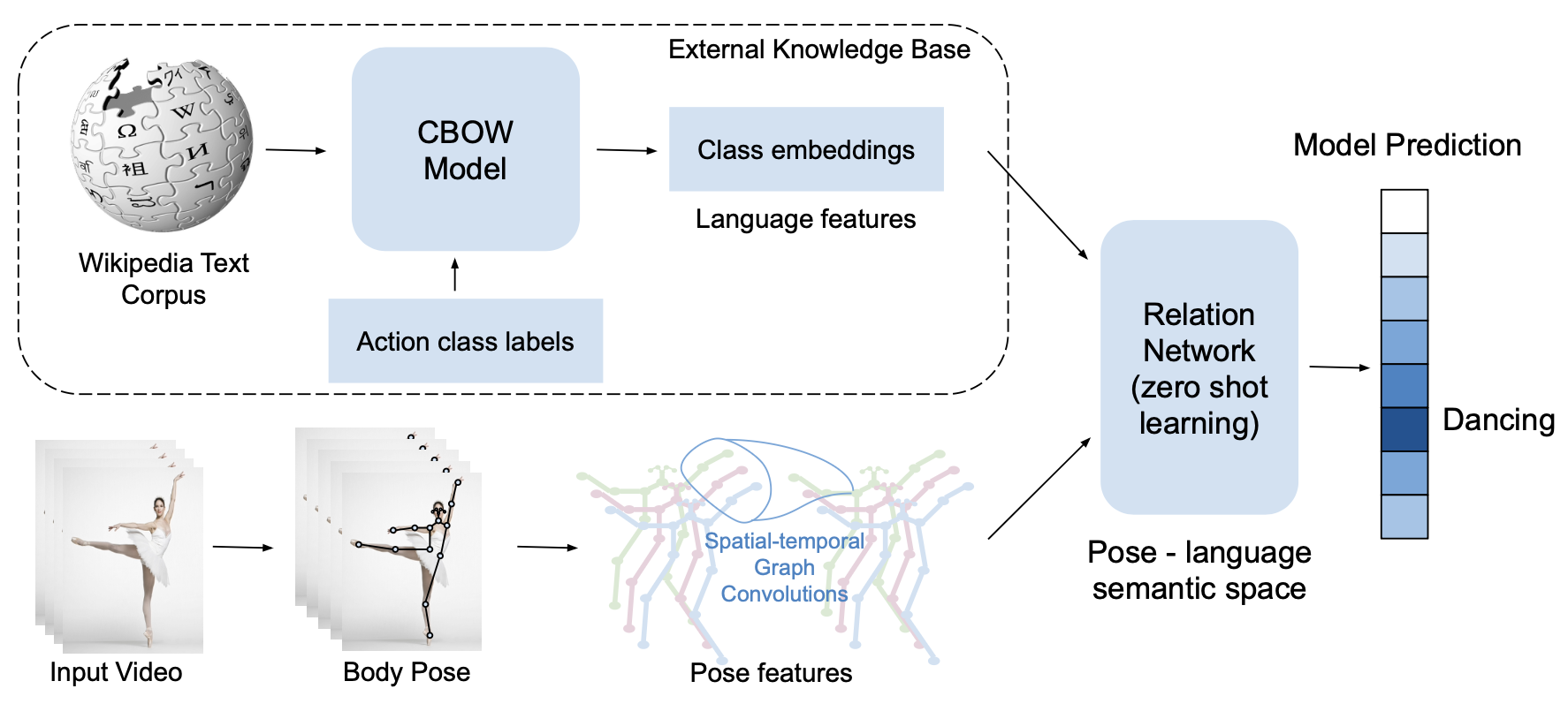
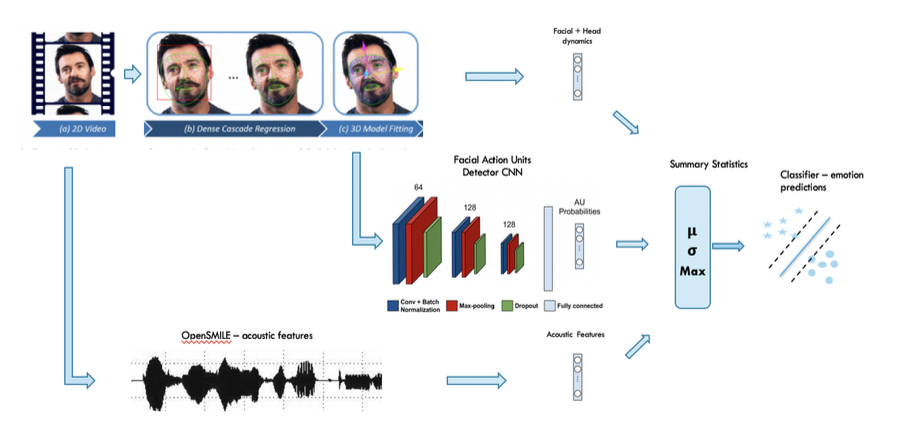
I’m an Applied Scientist who brings research to production, specializing in computer vision and multimodal
machine learning. My work focuses on two areas:
- Multi-modal learning - across images, text, video, audio, and structured data
- Synthetic data generation & annotation - with humans and AI in the loop to overcome
scarce or hard-to-label data
Areas of expertise: Foundation Model Post-Training, Multimodal Learning, Synthetic Data
Generation, Visually Rich Document Understanding, Visual Grounding, Chart Reasoning & Visual Question
Answering, and
Multi-node Distributed Training.
Looking ahead: I’m excited to apply my AI skills to physical robotics
(humanoid robots, self-driving cars) and healthcare (genomics, drug discovery) - areas where
research can have real societal impact.